
- By John W. Cox
- July 11, 2023
- Seeq Corporation
- Feature
Summary
Process manufacturers can leverage crew-based analytics within advanced analytics solutions to uncover operational insights undiscoverable via traditional industrial analytics.

Most manufacturing facilities maintain well-documented “point standards,” which list recommended setpoints and normal controller modes for maintaining optimal operation. These settings are chosen based on production, quality, energy use, and safety considerations, and it is expected they are applied consistently under normal circumstances.
In today’s data-driven world, it is increasingly common for manufacturers to monitor for and analyze operational anomalies to discover process inefficiencies and opportunities for optimization, but there are also significant insights to be discovered from process control-centric analyses. For example, point standard exception monitoring is a fundamental first foray into controller and crew-based data analytics (Table 1).

There are many additional insights for discovery beyond adherence to normal controller modes and optimal setpoints, such as monitoring crew-to-crew (shift-to-shift) differences related to regulatory control layer interactions, process performance, and maintenance effectiveness.
It is common for operating approaches to vary among crews as a result of differing collective personalities, process knowledge, and other human factors. But comparing and contrasting the way each crew utilizes automatic control strategies and operates/maintains process equipment can reveal valuable insights to optimize operations.
Barriers to implementing crew-based analytics
Implementing crew-based analytics presents some human-centric challenges in addition to others that are technical in nature. To start, there is an understandable fear of creating a negative and competitive environment between crews if not applied correctly.
Larger hurdles are found on the technical side, where oft-used spreadsheet-based analytics hold users hostage in time. These users miss out on a host of benefits provided by advanced analytics solutions, including:
- Contextualization: specifying when to conduct calculations for the most accurate, meaningful results
- Iteration at the speed of thought: confirmation of process signal characteristics, contextualized time periods, and calculation results as the analysis is developed
- Scaling efficiencies: maintaining a single set of calculations across similar equipment, controllers, and other assets
- Flagging abnormally high percentages of time spent in manual mode for controllers, over appropriate process running time periods
- Aggregating metrics over comparable time or process benchmarks, which may be “x” number of past crew shifts, or “y” number of process batches produced, rather than using elapsed time
- Excluding maintenance procedures that occur across shifts so differences between crew maintenance practices can be isolated
The following use cases highlight unique crew-based operational insights in addition to related key analytics workflows.
Monitoring crew interactions with the regulatory control layer
Use case 1: Monitoring unit-wide controller usage by crew
Regulatory control loops, such as PID controllers, typically run in automatic or cascade mode, making compensatory adjustments to keep the controller’s process value at or near setpoint. Switching controllers out of their normal mode can produce unforeseen impacts to raw material and energy consumption, product quality, and downstream equipment health.
To monitor controller usage, analytics application feature sets, like conditions and asset groups, are needed to make crew-specific calculations. These calculations can then be scaled across all controllers in a unit.
Conditions define when a state is true, and each instance of the condition is called a capsule. Asset groups are used to classify collections of similar items—such as equipment, operating lines, key performance indicators (KPIs), and more—via a simple point-and-click tool, mapping analogous process signals for each asset into a single structure.
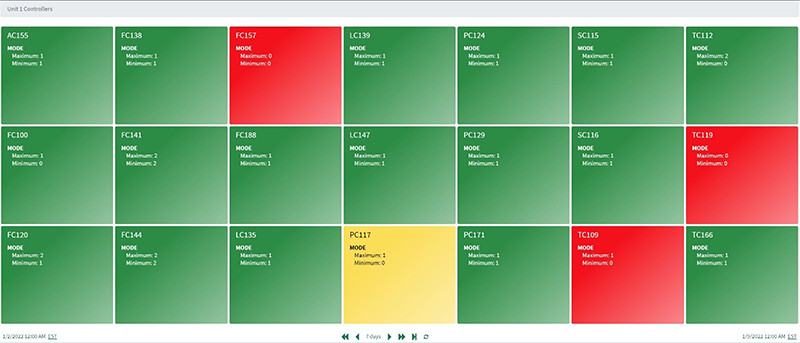
The example shown in Figure 1 contains crew-specific eight-hour shift capsules and controller mode signal data (0=manual, 1=automatic, 2=cascade) in an asset data structure for 21 controllers. The mode signal was trended for controller PC117 in lane one. The contextualized, crew-specific selection of manual mode for PC117 is evident by the Manual Mode Crew 1 and Crew 2 capsules just above the signal trends.

With the weekly percent time in manual by crew scaled for each controller, low controller usage was readily flagged in an asset-enabled treemap. The following insights were gleaned by comparing controller time in manual mode in crew-specific Figures 2a-c, where each controller box is colored green, yellow (manual > 15 percent of time), or red (manual > 50 percent of time):
- Unlike Crews 1 and 2, Crew 3 was running TC109 in automatic mode less than 50% of time. TC109 is a recently-commissioned controller designed to reduce product quality variability. Action was taken to further train Crew 3 on the importance of keeping this controller in automatic mode.
- All crews left FC157 and TC119 in manual mode. Crew feedback revealed the associated control valves needed resizing to avoid saturation issues, so maintenance was scheduled.
- Crew 3 ran PC117 in manual mode between 15 and 50 percent of the time, resulting in its yellow designation. Conversations with Crew 3 revealed PC117 always oscillates following an equipment procedure only scheduled during their shift, so an action item was assigned to the control engineer to address this oscillatory behavior.


Use case 2: Setpoint change magnitude and frequency
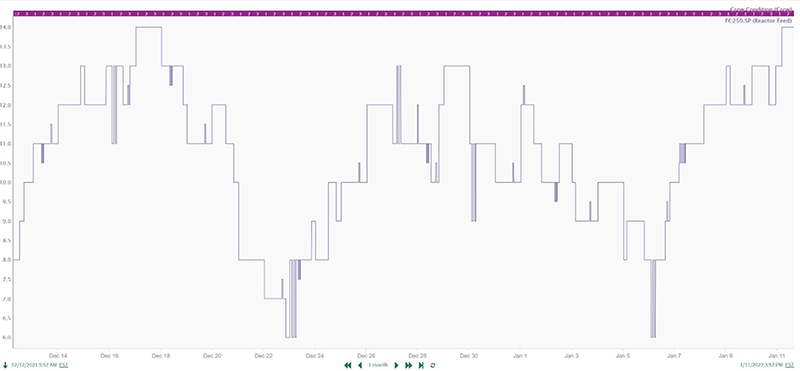
In another application, operators adjusted a reactor feed setpoint manually because reactor operation and quality are sensitive to throughput changes. Standard operating procedures limited setpoint changes to no more than 0.5 units, and no more than one adjustment every hour.
Starting with just the reactor feed setpoint signal and the crew schedule, contextualized as individual eight-hour capsules spanning each crew’s shift (Figure 3), Seeq—an advanced analytics solution—was used to categorize the magnitude and frequency of setpoint changes, and sort them out by crew (Figure 4).
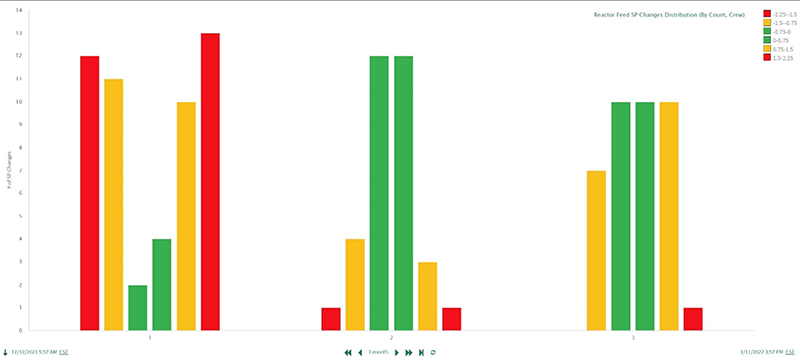
Crew 2 made the fewest changes in the yellow and red bins, and while this crew did well avoiding changes of larger magnitude, an analysis of setpoint change frequency (Figure 5) revealed too many changes in short spans of time.
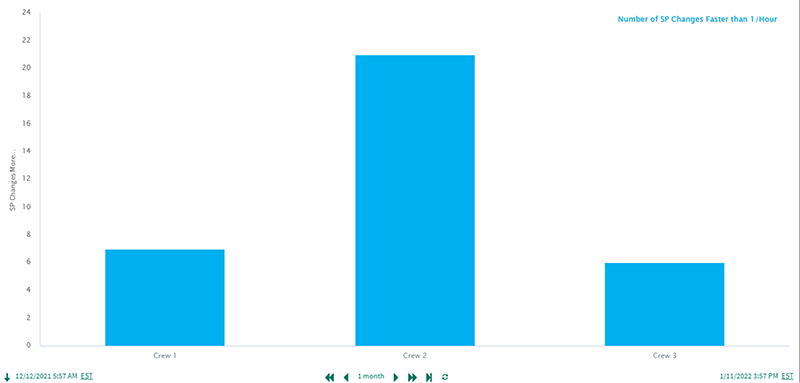
By allowing process conditions to smooth out, several additional setpoint changes could have been avoided, which would have improved overall operation. Patience is key when process dynamics are significant. These sorts of analyses are eye-opening to crews who are not always aware of how many adjustments are being made, and the impact changes have on operation.
Monitoring crew-influenced process performance
Use case 3: Energy usageIn a distillation column reboiler application, operation requires a significant amount of steam. The total used is dependent on how well crews maintain column conditions and feed consistency, primarily influenced by regular feed filter replacement. In Table 2, average steam usage was split by crew over the last ten shifts.

The data revealed the highest steam usage during Crew 3’s shift, below the performance benchmark. After conversing with Crews 1 and 2, Crew 3 made maintenance adjustments to reduce steam usage and get into the green.
Monitoring crew-influenced maintenance effectiveness
Use case 4: Isolating and quantifying maintenance performanceOptimal maintenance practices can be identified by examining frequency and timing of maintenance compared with quality or productivity KPIs.
In this example, pressure reduction is the KPI, which is achieved by cleaning equipment that fouls over its time in service. Analyzing this KPI would not have been possible without the right analytics software because it required the following key contextualization steps using capsules:
- Identify maintenance periods based on large pressure drops
- Capture an averaged pressure before and after maintenance
- Align the before/after pressures to the same point in time to calculate pressure reduction
- Identify the subset of maintenance periods completed by a single crew from start to finish
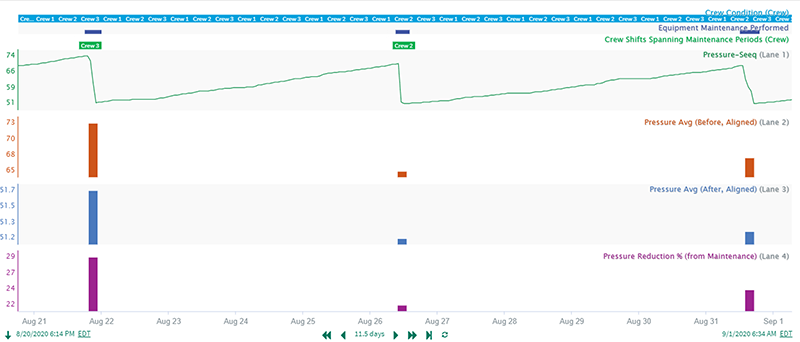
The “Pressure Reduction % (from Maintenance)” values, isolated to each crew (green capsules), were then analyzed to compare crew-to-crew maintenance effectiveness.
Facilitate an environment of knowledge-sharing and positive learnings
The use cases covered provide a small sampling of potential value in a frequently overlooked category of industrial data analytics. Capturing operator tendencies and behaviors—which can vary widely from crew to crew—is key to improving automation and control, and thereby maximizing production, reducing energy, and improving quality.Organizations must be careful applying crew-based data analytics because success hinges on promoting positive learnings to prevent a negative and competitive atmosphere. When implemented thoughtfully, crew-based data analysis can facilitate productive cross-team collaboration, whereby shift crews and process engineers work together to identify and resolve operational obstacles. In almost every case, this sort of collaboration leads to better team cohesion and greater operational efficiency.
All figures courtesy of Seeq
About The Author
 John W. Cox is a Principal Analytics Engineer at Seeq, where he works with customers on their advanced analytics use cases and provides technical input to new software features. Prior to joining Seeq, John enjoyed a 25-year career as a process control engineer at Eastman.
John W. Cox is a Principal Analytics Engineer at Seeq, where he works with customers on their advanced analytics use cases and provides technical input to new software features. Prior to joining Seeq, John enjoyed a 25-year career as a process control engineer at Eastman.
Did you enjoy this great article?
Check out our free e-newsletters to read more great articles..
Subscribe