



Across today’s industrial landscape, covering discrete manufacturing, automated distribution and critical power and water utilities, organizations are working toward the same goals: reducing unplanned downtime, finding root causes with less manual effort and predicting quality issues before they affect production. These goals are becoming harder to achieve as many industrial environments are constrained by legacy infrastructure, data silos and integration complexity.
Industrial AI and Physical AI, systems that combine digital intelligence with physical machine control, are often presented as the solution. Organizations are looking to AI-based solutions to bridge the gap between massive data sets and actionable production insights. However, in reality, many organizations encounter the same pattern: successful pilots that never scale. This is what I refer to as pilot purgatory.
The engineering trap: Why pilots don’t scale
The limitation is usually not the AI model. Pilots run in controlled environments, a small number of assets, stable data sources and limited integrations. In these conditions, even weak architectures can appear to work.
Problems begin when companies try to scale. At enterprise level, AI must work across different generations of equipment, legacy and proprietary industrial protocols, inconsistent data structures and naming standards and different operating conditions across sites and regions. When teams try to copy a pilot setup to new assets, they quickly discover the issue: each rollout needs new integration work, new data mapping and often model retraining. If the effort required for the tenth machine is almost the same as the first, ROI quickly disappears and the program stops.
The real issue: Architecture, not algorithms
Scalability does not break because of poor intelligence. It breaks because of integration complexity. Point-to-point integrations tightly connect systems to specific use cases. They work in isolation but fail when scaled across the enterprise. Many AI programs fail not because the models perform poorly, but because integration costs quietly grow faster than business value. To scale successfully, organizations must move away from individual solutions and toward a standardized architecture.
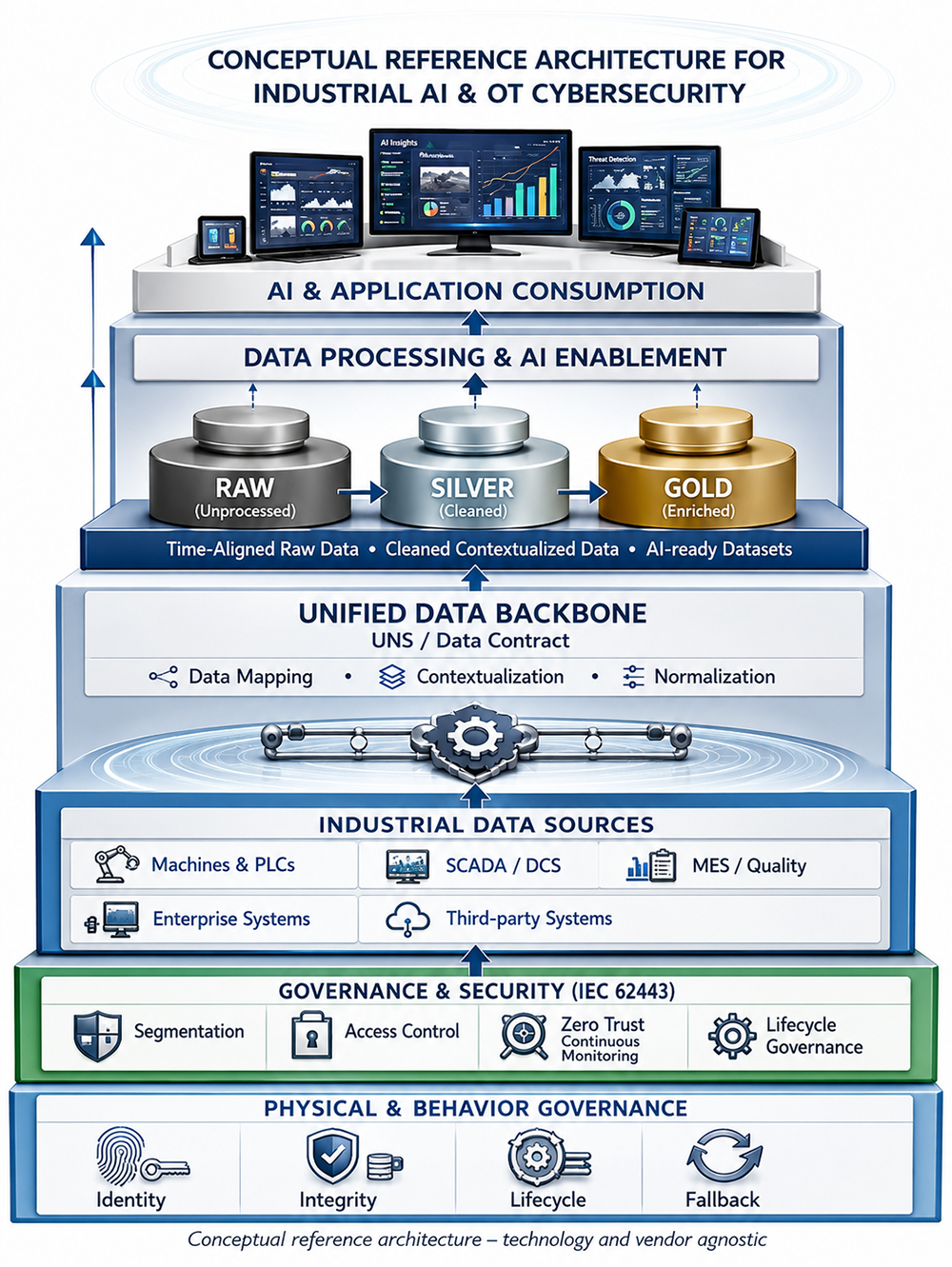
The solution: A standardized architectural backbone
Organizations that scale successfully adopt a reference architecture built on four core principles. These principles are drawn from direct program delivery across UK gas distribution, global automotive manufacturing and industrial AI platform development.
1. Protocol interoperability by design
A scalable architecture cannot depend only on modern standards like OPC UA or MQTT. It must also support legacy controllers and vendor-specific proprietary protocols, which remain critical to operations in most industrial environments. Ignoring them does not modernize the plant, it increases fragmentation. Interoperability must be designed in from the start, not retrofitted as an afterthought.
2. Unified Namespace (UNS) as the data contract
A Unified Namespace creates a single, trusted source of operational data that is standardized, context-rich and consistently structured. This separates data producers from data consumers, allowing AI models and analytics to be built against a stable data structure instead of being reworked for every asset or site.
When UNS is treated as a formal data contract, not just a messaging layer, it becomes the foundation for scalable and repeatable AI development. In practice, the UNS must be paired with consistent semantic modelling (asset hierarchy, units, states and events) so that data remains meaningful across sites and vendors. This greatly reduces engineering effort and operational complexity.
3. Cyber-governance built in from day one (ISA/IEC 62443)
Scaling AI without security is not sustainable. Successful architectures embed ISA/IEC 62443 cybersecurity principles from the start, including network segmentation, access control, asset visibility and lifecycle governance. When these are built in early, security becomes a support for scaling rather than a barrier to it.
In practice, IEC 62443 alignment reduces conflict between security, operations and engineering teams as systems expand. Clear ownership across OT assets, data products and AI models is essential to maintain lifecycle integrity as programs evolve across plants and regions.
4. A layered data processing approach for AI-ready data services
A scalable industrial AI architecture requires more than connectivity and structure — it requires predictable data processing at scale. Once data is standardized and contextualized through the Unified Namespace, it must flow through a layered processing model that ensures data quality, availability and reusability across use cases.
A layered data processing approach (commonly referred to as a Medallion Architecture) provides this structure across three tiers:
- Bronze: Raw, time-aligned operational data preserved for traceability
- Silver: Cleaned, enriched and context-aware datasets
- Gold: Analytics-ready and feature-ready datasets for AI and applications
This separation allows independent scaling of ingestion, processing and consumption, as well as reuse of data across multiple AI use cases. Industrial scale also depends on time synchronization and quality controls, timestamp integrity, sampling alignment and missingness management, to keep analytics and AI outputs trustworthy. By exposing data as services to AI and analytics layers, organizations avoid rebuilding pipelines for every new model or use case.
In practice, this architecture preserves deterministic control and safety logic at the edge, while platform and cloud layers are used for model training, optimization and cross-site governance. AI outputs are treated as bounded recommendations, with explicit fallback paths and human-in-the-loop controls for safety-critical operations.
The strategic takeaway
For large manufacturers and utilities, the AI journey must start with architecture, not algorithms. While the architectural principles are consistent, implementation patterns vary significantly across discrete manufacturing, process industries and regulated utilities. A unified, standards-based data backbone reduces repeated engineering work, improves data quality and trust, enables consistent AI deployment across sites and delivers measurable and repeatable ROI.
Industrial AI does not fail because the technology is weak. It fails when the foundations are treated as an afterthought.

